
Du récursif à l'itératif
Un mot sur la récursivité
La récursivité en informatique est un principe qui consiste à définir une routine en fonction d'elle même. Les algorithmes récursifs sont utilisés fréquemment, par exemple pour résoudre un problème de tri, définir une fonction ou une suite mathématique ou encore pour le parcours d'un arbre.
Performances
Bien que la notion de récursivité s'impose naturellement comme solution dans plusieurs problèmes algorithmiques, il est important de réaliser qu'une fois mis en place, un programme récursif chargera la pile à chaque nouvel appel de la routine. Il est alors important d'évaluer la performance d'une telle implémentation en temps, en mémoire et en stabilité.
Dérécursiviser
Si la solution récursive s'avère coûteuse ou instable (débordement de pile), on peut avoir recours à la suppression de la récursivité. Le principe générale de cette suppression consiste à utiliser un algorithme itératif en simulant la pile à l'aide d'une structure de donnée.
Exemple
Le parcours d'un arbre en profondeur consiste à parcourir tous les noeuds d'un arbre en commençant par l'exploration des feuilles à l'extrémité gauche de celui-ci et en remontant par le noeud père. Une mise en oeuvre typique de cette algorithme est le parcours d'un système de fichier.
Dans cette figure, les noeuds sont numérotés dans l'ordre de parcours en profondeur

Algorithme
L'algorithme récursif pour le parcours en profondeur d'un arbre est simple:
fonction parcourir(racine) debut
pour chaque noeud de racine faire
si le noeud n'a pas de fils alors traitement(noeud)
sinon parcourir(noeud)
fin
Le même algorithme en supprimant la récursivité peut s'avérer plus astucieux:
fonction parcourir(racine)
variables
$parcourus <- [racine] debut
empiler(racine)
tant que la pile n'est pas vide faire
$courant <- dépiler()
si $courant pas dans $parcourus alors
traitement($courant)
$parcourus <- $parcourus U courant
tant que $courant a des fils non parcourus faire
$fils <- getFils($courant) si $fils n'a pas de fils alors traitement(fils)
sinon
empiler($courant)
empiler($fils)
sortir de la boucle
fin
Le principe de ce dernier algorithme repose sur l'empilement lorsque au moins un noeud fils existe et de l'arrêt lorsque la pile est vide.
Une implémentation adaptée au problème du parcours d'un système de fichiers écrite en Python peut être téléchargée ici.
La récursivité en informatique est un principe qui consiste à définir une routine en fonction d'elle même. Les algorithmes récursifs sont utilisés fréquemment, par exemple pour résoudre un problème de tri, définir une fonction ou une suite mathématique ou encore pour le parcours d'un arbre.
Performances
Bien que la notion de récursivité s'impose naturellement comme solution dans plusieurs problèmes algorithmiques, il est important de réaliser qu'une fois mis en place, un programme récursif chargera la pile à chaque nouvel appel de la routine. Il est alors important d'évaluer la performance d'une telle implémentation en temps, en mémoire et en stabilité.
Dérécursiviser
Si la solution récursive s'avère coûteuse ou instable (débordement de pile), on peut avoir recours à la suppression de la récursivité. Le principe générale de cette suppression consiste à utiliser un algorithme itératif en simulant la pile à l'aide d'une structure de donnée.
Exemple
Le parcours d'un arbre en profondeur consiste à parcourir tous les noeuds d'un arbre en commençant par l'exploration des feuilles à l'extrémité gauche de celui-ci et en remontant par le noeud père. Une mise en oeuvre typique de cette algorithme est le parcours d'un système de fichier.
Dans cette figure, les noeuds sont numérotés dans l'ordre de parcours en profondeur
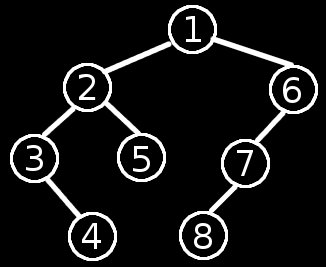
Algorithme
L'algorithme récursif pour le parcours en profondeur d'un arbre est simple:
fonction parcourir(racine) debut
pour chaque noeud de racine faire
si le noeud n'a pas de fils alors traitement(noeud)
sinon parcourir(noeud)
fin
Le même algorithme en supprimant la récursivité peut s'avérer plus astucieux:
fonction parcourir(racine)
variables
$parcourus <- [racine] debut
empiler(racine)
tant que la pile n'est pas vide faire
$courant <- dépiler()
si $courant pas dans $parcourus alors
traitement($courant)
$parcourus <- $parcourus U courant
tant que $courant a des fils non parcourus faire
$fils <- getFils($courant) si $fils n'a pas de fils alors traitement(fils)
sinon
empiler($courant)
empiler($fils)
sortir de la boucle
fin
Le principe de ce dernier algorithme repose sur l'empilement lorsque au moins un noeud fils existe et de l'arrêt lorsque la pile est vide.
Une implémentation adaptée au problème du parcours d'un système de fichiers écrite en Python peut être téléchargée ici.
posted by David at 9:30 AM
Share on LinkedIn
Share on Twitter
![]()

5 Comments:
Salut,
Tu dis que la simulation d'une fonction récursive est moins coûteuse et plus fiable que la fonction récursive elle-même.
Mais en quoi simuler une pile est moins coûteux que d'utiliser la pile elle-même ?
Pour moi un algorithme récursif restera peu efficace quelque soit la forme sous laquelle il se trouve; et à la limite allouer sur le tas une 'pseudo-pile' reviendra plus cher que d'empiler des adresses de retour.
Salut,
merci pour les commentaires. Ca fait toujours plaisir, surtout si c'est pour apporter des corrections.
Non, je n'ai pas dit que la simulation d'une fonction récursive est plus efficace.
J'ai surtout voulu dire qu'il faut d'abord évaluer la performance requise par rapport à la capacité physique de l'ordinateur.
Une application où l'élimination de la récursivité par un algorithme itératif s'avère avantageuse, c'est sur la construction d'une table de symboles pour l'analyse sémantique bottom-up en compilation.
LOL c'est la première fois que je tombe sur un blog mauricien qui traite d'un sujet si précis et technique. En tout cas, keep it up!
Je trouve votre blog en utilisant google et je dois dire, c'est parmi les meilleurs articles bien écrits que j'ai vu depuis longtemps.
J'ai typiquement cette problématique àrésoudre .. passer du récursif à de l'itératif ... j'vais voir si mes neurones arrivent à passer le cap de la compréhension de la technique ;)
Enregistrer un commentaire
<< Home